






画像化されている文字を Googleドキュメントの OCRを使ってテキストを抽出するやり方
画像化されている文字や書籍などの文章、手書きで書いた文字などテキストデータとして抽出したいと思ったことはないでしょうか?
GoogleドキュメントのOCRやGoogleレンズを使えば簡単にテキストデータ抽出することができます。
抽出テキストデータは入力した文字と同じようにコピー&ペーストすることもできます。
OCRとは
光学文字認識 → Optical Character Reader(オプティカル キャラクタ リーダー)の頭文字がOCR(オーシーアール)です。
画像の中から文字を見つけ出して、テキストデータに変換する技術のことです。
認識率(精度)を上げるためには?
1.高い解像度でスキャンする。
2.スキャンは白黒で。
パソコンからの手順
パソコンからデータを抽出するときにはOCRを使うとよいでしょう。それでは手順です。
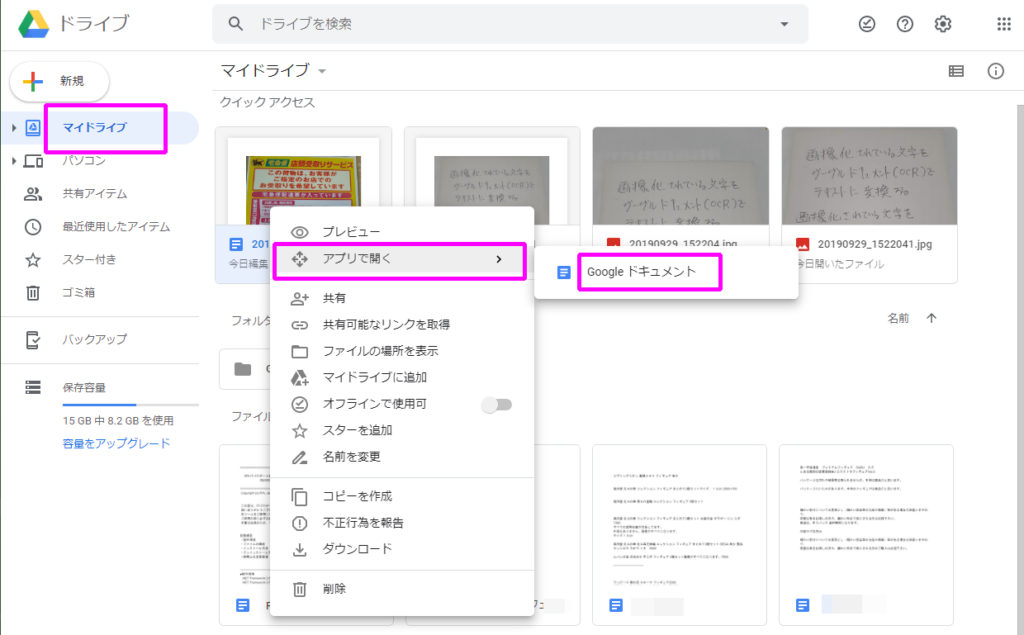
パソコンからグーグルドライブを開いてテキストを抽出したい画像を選択して右クリックして「アプリを開く」から、「グーグルドキュメント」をクリックします。
たったこれだけです。
何回か試してみましたが下記の印刷物のものであれば9割くらいはテキストに変換できそうです。

メモしたものでも6割くらいは変換できそうです。
もともとグーグルドキュメントのOCRは手書きには対応していないので6割も変換できれば上出来でしょうか。

テキストに変換できるファイルは、JPEG・PNG・GIF・PDFです。
スマホから抽出するならGoogleレンズがおすすめ。
書籍などは、ほぼ変換できるので重要なページはスマホで撮ってテキストにして保存してます。
皆さんも一度試してみてはいかがでしょうか。


コメント